Choosing The Right Data Platform for Business Intelligence Consultancy Services
Our Data Platform Consultants can help you choose and build the right Data Platform for you
With over 30 years of experience in assisting clients with their data and business intelligence requirements we are well equipped to help you along your business intelligence and data analytics journey.
Our Data Platform Consultants can help you choose and build the right Data Platform for you
Your Data Platform will serve as an enterprise wide data hub that can service a wide variety of data challenges within your organisation. With over 30 years of experience in assisting clients with their data and business intelligence requirements we are well equipped to help you along your business intelligence and data analytics journey, starting with selecting the right data platform to suit your needs to day and into the future.
What Is a Data Platform?
A Data Platform is typically comprised of many components that can be combined in a modular fashion to suit you evolving data needs. Let us take the Microsoft Azure Data Platform as an example.
The Azure Data Platform is a family of data services that can be combined as your needs require to build your enterprise wide data hub.
Traditional Relational Data Pipelines
Integrating data from disparate sources, types, locations and custodians
Structured, Semi-Structured, Unstructured
On-Premise/Private Cloud/Public Cloud
SaaS/APIs
IoT
Semantic Modelling for simpler analysis and visualisation in tools such as Power BI
Direct connectivity to raw unstructured data
Real-time streaming analytics
Big data transformations
Data Science, Machine Learning and AI
The principal building blocks of this data hub are the Data Warehouse (Azure Synapse) for structured data and Data Lake (Azure Data Lake) for semi-structured and unstructured data. The Azure Synapse Analytics service is bringing these 2 components together to provide a common entry point to all these data sets simplifying user access to data from a wide range of tools and speeding up the provisioning of new data sets.
Azure Data Factory provides orchestration of the ELT (Extract, Load, Transform) process to pull data from many different sources into the Data Lake for storage or staging for onward transformation to the Data Warehouse or other Data Processing components.
Azure Databricks is Microsoft’s implementation of Apache Spark in Azure, a distributed computing framework that enables high speed processing of data for complex transformations and AI solutions.
Collectively these components form the basis of the Azure Modern Data Warehouse and moving forward are bring brought together under the Azure Synapse Analytics Studio.
Additional Components
There are many additional Azure Data Service components that can extend the data platform beyond conventional analytics and reporting.
Real-time/Streaming Analytics
Azure Event Hubs collect data streams from client applications as they occur and preserve the sequence of events. Multiple consumers can connect to the Event Hub to retrieve messages for their own processing requirements including storage within the Data Lake.
A Stream Analytics job can collect messages from the Event Hub in Real time to provide a hot path straight into Power BI to populate streaming dashboards.
Data Science, Machine Learning, AI
Azure ML is an enterprise grade Machine Learning service enabling developers and data scientists to effectively collaborate on the building, training and deployment of machine learning models
Cognitive Services makes accessible without the need for extensive machine-learning expertise by exposing APIs that can be called from Databricks notebooks to quickly integrate common AI usage patterns, such as chatbots and sentiment analysis for instance.
Integration & Automation
Power Automate (Office 365), Azure Logic Apps & Azure Functions (Azure) enable the development of serverless integration patterns that can automate processes between applications on a scheduled or event triggered basis.
Azure Cosmos DB is a globally distributed, multi-model database service which is designed to deliver highly scalable worldwide single-digit-millisecond response times to globally distributed applications and web services through a variety of APIs.
Power BI
Power BI continues to evolve at a rapid pace, as does its potential role within the Enterprise Data Platform.
Data Connectivity
With regards to the Data Platform outlined above, Power BI can be connected into the Data at many layers
Shared Enterprise Semantic Model in Analysis Services
Collated and Managed Data Sets through Synapse Analytics Data Warehouse
Raw untreated data from the Data Lake
Direct to source data applications and data services
Modelling
Much of the data transformation and modelling work can now be consolidated and centralised within the Power BI service, particularly under Power BI premium licensing, potentially eliminating the need for a separate dedicated modelling platform such as Analysis Services.
Dataflows
Shared Datasets
Large Models (Premium (preview))
Aggregations
RLS
Power BI Modelling tools in Synapse Studio
Building a Data Hub
Many organisations now have, or should have, an ambition to expand on the functionality and scope of their traditional Data Warehouse, which is probably well established and an key part of current business intelligence and reporting solutions, to implement a Data Lake alongside to create an easily accessible Data Hub to suit the many different types of data and consumers that they need to service.
Data Warehouse vs Data Lake
The principal difference between a Data Warehouse and a Data Lake is that the Data Warehouse has a rigidly defined schema to provide interrogation of structured data sets through languages such as SQL.The Data Lake conversely does not have any specifically defined schema and therefore can be used to store many different types of data, both structured, semi-structured and unstructured. This storage may simply be used as a staging area for onward transformation into the Data Warehouse or accessed directly as a store in its own right by applications that draw value from accessing data in its rawest form.This flexibility brings with it inherent challenges with managing the quality and quantity of data, controlling and governing access to data, keeping track of the data sets that are available and avoiding duplication, etc.It is in this area of defining some golden rules and best practices where Ted Baker feel they would benefit from some additional knowledge and guidance to avoid the Data Lake becoming a Data Swamp.
Data Lake Principles
The following is provided as a guide to some of the general principles that should be considered in developing Data Lake golden rules for the organisation.
ELT Patterns
Ingest Early, Transform Late. In data lake environments, data will typically be moved first with little or no treatment of that data from its raw form to land in the data lake. Transformations can then be performed later and moved through distinct zones in the lake, performed in the Data Warehouse if that is the destination, or virtualized within the analytics tools, such as Power BI, themselves.
Persist Raw Data. Source data is generally preserved in its native from in the Lake. Any onward transformations are applied to copies of the data to the original untampered source can always be returned to if required for a “truer” view of the original data./li>
Zones
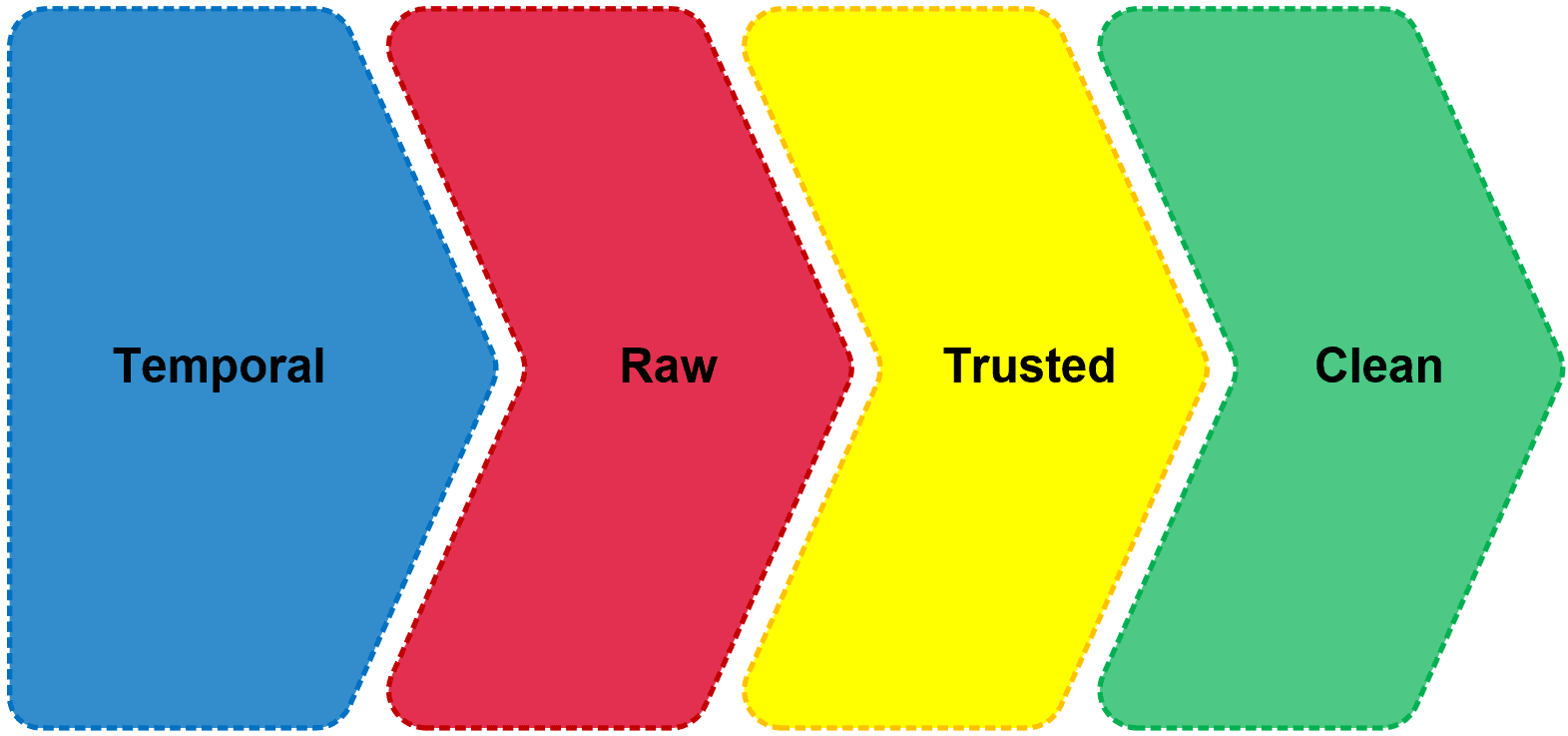
Defining multiple zones within the data lake allows for the physical and logical separation of distinct datasets which will help to keep data organised and also to manage security and access control. A common zone pattern may look as follows:
Temporal Zone – Ephemeral or short-term data which is often discarded once it has completed its role in a broader process. Staging data into the Data Warehouse may be an example.
Raw Zone – Long-term storage area for raw, untreated data. This enables the storage and preservation of detailed data from source systems in its most native form and can be repurposed for multiple applications. It is important to keep track of the data in this zone and potentially ensure that sensitive data may require encryption or pseudonymisation for instance
Trusted Zone – Another Long-term storage area that will store data from the Raw Zone that has passed through Data Quality or validation processes and can act as a trusted source for reporting purposes.
Clean Zone – Stores data which has been transformed or enriched by other tools such as Databricks and passed back into the Lake
Privacy & Security
With so much data potentially available for storage in the lake it is important to keep track and have robust controls of who can do what, what data is available and where further security may be necessary.
Establish policy-based rules and access control of who can load what, when and how to the lake
Document data as it enters the lake through tags, metadata and lineage and potentially build a data catalogue to enable users to find existing data sets, avoid duplication and track origins of data if it needs to be challenged.
Consider the content of the data sets and be aware of governance and compliance issues, such as GDPR and Personally Identifiable Information where additional security measures, such as encryption, may be necessary.
File Formats and Types
Whilst it is technically possible to store pretty much anything in a Data Lake, certain file types and considerations will better serve some subsequent process than others.
Number and Size. Consider the next primary consumer of the data when planning how to potentially split data files. Polybase in Azure Synapse typically performs more effectively with many smaller files that can be well parallelised. Big Data tools, such as Hadoop however perform better with smaller numbers of larger files.
File Type. As above, consider the consumer for favourable file types. Databricks transformations can produce Parquet files for instance which perform extremely well for high volume queries and aggregations but may not be well suited to more granular queries.
Building Your Data Platform - Where do you start?
Start by contacting PTR and we can take you through your options for selecting and designing the Data Platform solution that is right for you. We can assess your requirements and put together a per day or project based consultancy proposal to get you to where you need to be. It is vital that you see an early return on investment without committing to an extremely high budget and the best way to do that is to let us work with you to break your requirements down into manageable and affordable stages.We are a big fan of Proof of Concepts (PoC) where we will work with you to choose an initial business process and Data Platform requirement that can be used to test the water and gain stakeholder confidence. A POC can help you to:
Prove a chosen data platform architecture as fit for purpose
Educate and equip your team with the new skills they will need going forward
Carry out sizing and capacity planning to assess the full cost and budget implications
Provide a relatively quick set of results to demonstrate the potential Return on Investment and benefits of a central Data Hub
Following a successful PoC the full data platform roadmap can be planned. By looking at the long term goals we can pull out the key business processes that need to be brought in to the data platform solution, and in line with your data strategy can build the roadmap and timeline to start the journey.It will be a journey, and the direction may from time to time change direction as business priorities change, but with a strong data strategy and a well thought out data platform roadmap these priority changes can easily be accommodated.Through our tailored data platform and data strategy consultancy services we can work with you to find the right solution and the right path for you.
About PTR
PTR have held Microsoft accreditation since 2005, currently holding Gold Partner Status for Data Platform and Data Analytics. We have been working with clients on Data Strategy, Analytics and Business Intelligence solutions for over 30 years across a wide range of platforms and vendor solutions. We pride ourselves on combining first rate technical skills with an ability to communicate complex ideas, technology, and data effectively, and working with clients to develop a deep understanding of their business processes and data objectives.
Other related documents:
Membership Engagement Analytics Solution
Share This Post
Frequently Asked Questions
Couldn’t find the answer you were looking for? Feel free to reach out to us! Our team of experts is here to help.
Contact Us