Technology
Single Source of Truth Repository - Where should it be?
Lakes, warehouses and lakehouses, each slightly different in their own way. At PTR we specialise in breaking down the confusing jargon and guiding you through choices about reliable storage solutions as part of our consultation on your data strategy.
Your Single Source of Truth – What is it and how do I get it?
Every data driven organisation needs a Single Source of Truth (SSOT), a trustworthy repository for the vast amounts of data your company holds. It is the trusted data base from where your precious information is queried, analysed and shaped into reports. Such data repositories are known variously as lakes, warehouses and lakehouses, each slightly different in their own way.
At PTR we specialise in breaking down the confusing jargon and guiding you through choices about reliable storage solutions as part of our consultation on your data strategy. Please find our glossary of terms here.
In this article we will be looking at the concepts behind your Single Source of Truth and the different options available before guiding you beyond the definitions to look at what might work for you in practice. So, let’s get stuck in!
Why do I need a Single Source of Truth?
In short:
To avoid reporting inaccuracies, inconsistencies, conflicts
To avoid security breaches caused by direct data access and user downloads
To avoid out of date sources being used for reporting
To avoid duplication of data around the business
To avoid data silos in separate systems
To avoid unapproved, non-validated data being taken to be the truth
To avoid ambiguous language and terminology across the business
To avoid unnecessary errors
To avoid making the wrong business decisions
Or to look at it in a more positive light:
To improve accuracy and trust in reports
To conform to data governance policies and protect data for unauthorised access and distribution
To ensure up to date data is used for reports
To integrate all business data into one "joined up" data set for a 360 view of your business
To publish approved reports based on validated and quality data
To ensure the same algorithms, calculations, names and descriptions are used throughout your entire organisation
To drive better and more informed business decisions from your data
Driving greater accuracy
Too many times we see anomalies in reports presented by different parts of the business resulting in conflicting or inconsistent figures being presented to drive business decisions. These differences are often caused by each person sourcing their own data and applying their own cleansing rules, categorisations, and calculation definitions. Excel is wonderful, but it relies on individuals putting formulae together to cleanse, filter and calculate on data.
Another issue that we see frequently is security breaches caused by source data being accessed and downloaded to local storage with minimal security and protection. Or sensitive data being made available by granting direct access to live source systems for reporting and analytics purposes.
Allowing people to directly access disparate data sources and manipulate them in their own analytics environment without any central checking, validation or approval process is potentially going to lead to bad data being presented as the truth and bad business decisions being made as a result.
In our article from last month’s newsletter, we saw examples of where AI has gone wrong and highlighted that poor quality data fed into AI algorithms can result in poor conclusions and actions. Using a single source of truth as the source for your AI projects will significantly improve the quality of outcomes from your AI algorithms.
Single Source of Truth - Definition
A single source of truth (SSOT) is a secure central repository of data that is accurate, validated and trusted. It is your organisation's master data for analytics, reporting and business operations.
The content of your single source of truth repository will have been cleansed, error-checked and approved as trustworthy and accurate. It will also handle appropriate security protection to ensure data is only accessible by those that have the required level of authorisation to access it.
Single Source of Truth – Benefits
All your data in one place
A single definition for all your business metrics (calculations)
A single data dictionary ensuring no ambiguity of names and formulae across different parts of the business
Data Governance policies to protect and serve data securely
A single well defined data access and security policy
Data needs cleaning only once
Cleansed data integrated into a single storage location
A single authoritative data source for all business use and reporting
Data you can trust every time
Where Should I Put My Data?
You have many choices when it comes to deciding where you should locate your Single Source of Truth data. These are the most common choices;
Lake
Lakehouse
Data Warehouse
Semantic Model
Whatever your choice it will only really be a Single Source of Truth if it is well regulated and used consistently for all business, analytics and reporting purposes.
Without a SSOT and a strong set of procedures around its use, multiple silos spring up across departments or functions each with their own copy of the data, definitions, calculations and access rights. Inconsistencies crop up, for example, different definitions for key business metrics, different rules for cleansing data, different names for the same thing, or the same name for different things!
Once you have made the decision that you can benefit from a SSOT you can think about the right location and platform for you.
Whether you decide to create your SSOT in a lakehouse, data warehouse or a semantic model will largely come down to these factors:
The data governance requirements in your organisation - access control, security, audits
The number of disparate data sources around the business
The volume of data to be stored
The type of data to be stored
The quality of the source data and how much cleansing or transformation might be required
Data ownership
Data accessibility
How many people or tools need access to the SSOT
Is a snapshot or point in time view of the data required?
Do you have any machine learning requirements, such as predictive and trend analysis?
What internal resource and skills do you have available within your organisation?
What is your budget and timescale for delivering your SSOT solution?
SSOT – data location options explained
Choosing a Data Lake SSOT
A data Lake is simply a store for raw data, both structured and unstructured. There is no structured querying capability or transactional behaviour support with a Lake. It is purely a repository. Technically you could ingest your data into a lake, use external tools to clean, transform and prepare the raw data and then drop it as a trusted data set, back into the Lake. But this does not make your SSOT data easily available to the off the shelf reporting and analytics tools that business users are likely to have access to.
Choosing a Data Warehouse SSOT
A Data Warehouse is the perfect choice for your SSOT if you are predominantly ingesting structured data, or are planning on transforming your unstructured data into a structured format.
A Data Warehouse contains a static copy of the data at the point in time of the last load, typically once per day. The data is then stored in its final trusted format.
This is the more traditional approach to building a SSOT and will often be implemented using SQL coding to cleanse, transform and prepare the data, before being loaded into a star schema set of Fact and Dimension tables.
With a Data Warehouse you can take a snapshot of your data at a particular point in time, which can then be passed into the reporting and data analytics world. In the event of data loss or corruption you can return to an earlier point in time which allows data recovery.
With a Data Warehouse you can also track particular changes in your data such as Slowly Changing Dimensions (SCD) behaviour or changes in entity over time.
Choosing a Lakehouse SSOT
A Lakehouse is a hybrid of a Lake and a Data Warehouse, combining the best of both worlds. The Lake's flexible schemas and fast moving data, combined with the Warehouse's structured queries and transactional behaviour creates a perfect solution, combining flexibility, performance and accessibility and catering to historic and real time analytics.
A Lakehouse is the perfect location for your SSOT if your data is comprised of both structured and unstructured data. Unstructured data is unpredictable in its content type and format so is more challenging to cleanse, prepare and store in a fixed structured way. But in a Lakehouse environment you can use tools like Databricks to process the raw unstructured data as needed, ready to be delivered to the data analytics tools which will turn it into reports and ultimately deliver insights.
You are not limited to applying this method of data preparation to unstructured data, Databricks can be used to prepare and transform your structured data on demand as well.
How it works
With the very latest data drop being served up from across all your data sources this approach gives you close to "real time" reporting and analytics across large volumes of business data.
Data is ingested in its raw state, whether structured or unstructured. This means a single platform, storage location and Extract Load Transform (ELT) toolset can be used for all your data sources regardless of source type and location.
Databricks implements Apache Spark technology to enable all types of data to be cleansed, prepared and transformed in one place. Capable of processing massive data sets very quickly, Apache Spark is suitable for on-demand execution, delivering straight to an analytics tool, or to a persisted structure such as a Data Warehouse.
A Medallion Architecture is often applied to Lakehouse SSOT solutions, providing a layered or tiered approach to taking your raw data through to a clean, trustworthy state for reporting and analytics. The Medallion Architecture offers three distinct layers: • Bronze - raw data • Silver - cleaned data • Gold - curated data Raw data is not cleaned or transformed in anyway. Lakehouse storage generally retains change history so that you can go back and see what your data looked like at any given point in time, enabling data snapshotting and data recovery to a point in time, as well as handling slowly changing dimensions by picking up changes between data drops.
Clean data will have been processed to address issues in the raw data such as adding missing values, removing outlier values, removing duplicate records, joining to other datasets, filtering out unwanted records, aggregating data.
Curated data is your gold standard trusted data, guaranteed to be accurate and true. Gold data is ready for reporting and data analytics consumption.
Data quality is key at every stage of building your SSOT. Data validation and data quality checks will need to be built in to the processing layers to ensure you end up with an accurate and trustworthy dataset.
Choosing a Semantic Model SSOT
If you are looking for a quick and budget friendly way of delivering a trusted data set for reporting and analytics a Semantic model might be the way to go. Semantic models are designed to present data in a way that aligns with business concepts and terminology, making it easier for stakeholders to interact with and understand the data without needing to know the intricacies of the underlying data structure.
However it is more common to create a Semantic model from a Lakehouse SSOT or a Data Warehouse SSOT.
A Semantic model allows for an extra layer to be added to your SSOT solution, which captures the business meaning and relationships between different data elements.
Instead of relying on reporting or analytics tools such as Power BI, Excel, Tableau (and many more) to have complex formulae created within reports and workbooks themselves, a Semantic Model provides a single central access point to not only your SSOT data, but also provides a SSOT view of your business metrics and key performance indicators.
This is a huge benefit as there is one central, approved set of definitions for
A single set of entity and field names (your business wide Data Dictionary)
A single definition for all business calculations (KPIs and metrics/measures)
Approved business hierarchy definitions to ensure data is used in the correct manor and drilled down to in sensible, meaningful ways
Your entire business data and logic is created within a single shared semantic model and delivered directly to dashboards that focus on telling a story and allowing users to interact with them for questions and answers.
A key difference between a Semantic Model and a Lakehouse or Data Warehouse is that a Semantic Model is memory resident - all data, business hierarchies, relationships and measures are stored in an in-memory cache rather than a persistent store.
On the one hand a cached semantic model is good for performance and speed of delivery, and relationships, hierarchies and measures give context to the data that we don't get from a Data Warehouse or a Lakehouse.
The downside to this, is that it is very resource intensive and has no capability to handle data snapshotting or slowly changing dimension functionality.
Summary
Semantic model is memory resident and does not support snapshotting or slowly changing dimensions, but it does include all the business relationships, logic and hierarchies creating a perfect SSOT for self-service and business served reports and dashboards.
A Data Lake provides storage for structured and unstructured data and can act as the repository for your SSOT, but no native support to present that data in a ready to use format by standard user-ready tools.
A Data Warehouse offers persisted storage of clean and structured data, organised into a star schema, supporting historic, point in time and slowly changing data reporting and analytics through a standardised SQL interface making it easily accessible from standard user tools. It does not offer business context via a built-in data dictionary, hierarchies, business relationships and measures - these will need to be added through the reporting layer.
A Lakehouse combines the best of Lakes and Warehouses to offer a performant SSOT ideal for historic and real-time reporting supporting all the functionality of Data Warehouses. Storage and compute are separated in a Lakehouse enabling scalability to be handled independently for storage and processing. It does not offer business context via a built-in data dictionary, hierarchies, business relationships and measures - these will need to be added through the reporting layer.
So where does that leave us?
The ideal world might be a Lakehouse feeding a Data Warehouse with a Semantic Model layered on top. This delivers the best of everything for an enterprise-grade Single Source of Truth, encompassing high quality data, business context, terminology and metric definitions.
The reality will most likely be somewhere in between.
Entry Level SSOT Solution - Semantic Model Only
A small organisation with limited budget, time and internal resource might opt for an initial self-contained Semantic model that directly ingests disparate datasets and handles all the cleansing, transforming and preparing of data within the semantic model itself. The business context would be provided by modelling tables, relationships and hierarchies and defining measures and key performance indicators within the Semantic Model. Something like Power BI or Microsoft Fabric combined with Power Query Dataflows might be deployed.
Mid Solution - Data Warehouse
Integrated, cleansed, transformed quality data is stored in a data warehouse star schema structure. Business context is provided using reporting tools to connect directly to the data warehouse tables to ingest required data and model it specifically for report functionality. A potential issue with this approach is multiple reports ingesting the same data but implementing different relationships, hierarchies and measure definitions. The data itself is SSOT, but the reports are not. Platforms such as Azure SQL, Azure Synapse or Fabric would be contenders for hosting a data warehouse.
Mid Solution - Data Warehouse Plus Semantic Model
Integrated, cleansed, transformed quality data is stored in a data warehouse star schema structure. Business context is provided by creating an enterprise shared Semantic Model that ingests data from the Data Warehouse. The data provides the SSOT dataset and the Semantic Model provides the SSOT business context, language and logic.
Enterprise Solution - Lakehouse and Semantic Model
A Lakehouse serves your SSOT data and the Semantic Model provides the SSOT business context, language and logic. Microsoft Fabric offers the perfect platform for hosting such an enterprise solution.
Enterprise Solution - Lakehouse, Data Warehouse and Semantic Model
A Lakehouse serves your SSOT data to a data warehouse which makes your SSOT data accessible via a standard SQL interface, and the Semantic Model provides the SSOT business context, language and logic.
The following diagram shows all the bells and whistles in an SSOT solution designed around the Microsoft Azure Data Lake, Azure Synapse Analytics and Power BI services and platforms.
This is just one set of platforms, but there are many to choose from depending upon your requirements.
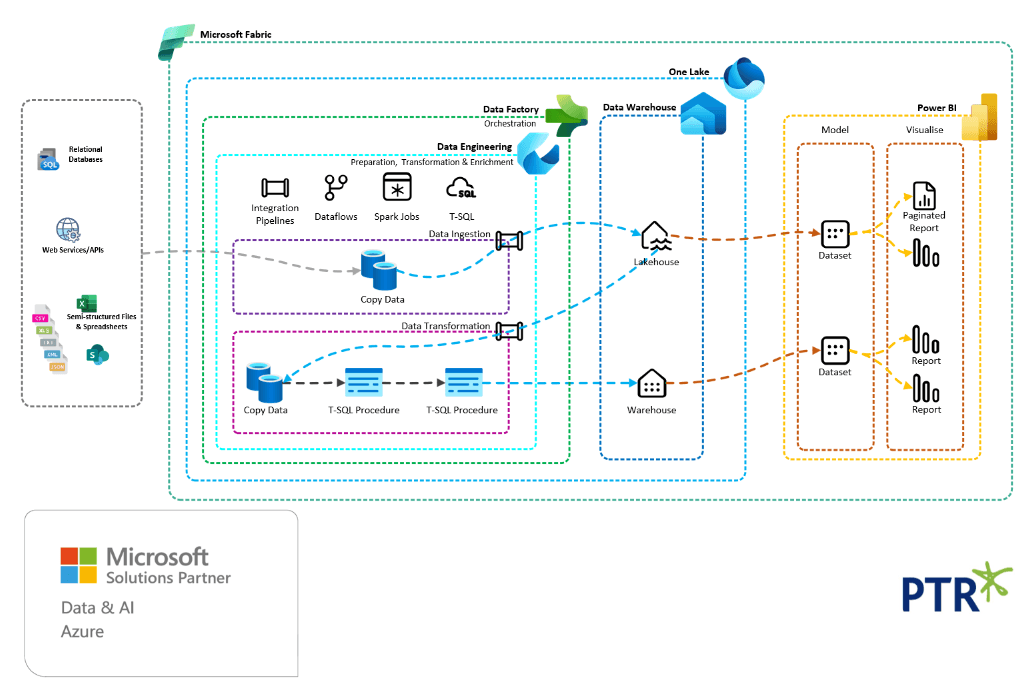
The latest Data and Analytics platform from Microsoft is Microsoft Fabric, featured in our December newsletter. With Microsoft Fabric your entire data solution can reside within one workspace in a single data platform.
The following diagram shows a potential Microsoft Fabric SSOT solution architecture.
We know that every business is different, and that with this article we have only begun to outline the possibilities for you here!
Share This Post
Mandy Doward
Managing Director
PTR’s owner and Managing Director is a Microsoft MCSE certified Business Intelligence (BI) Consultant, with over 30 years of experience working with data analytics and BI.



Frequently Asked Questions
Couldn’t find the answer you were looking for? Feel free to reach out to us! Our team of experts is here to help.
Contact Us